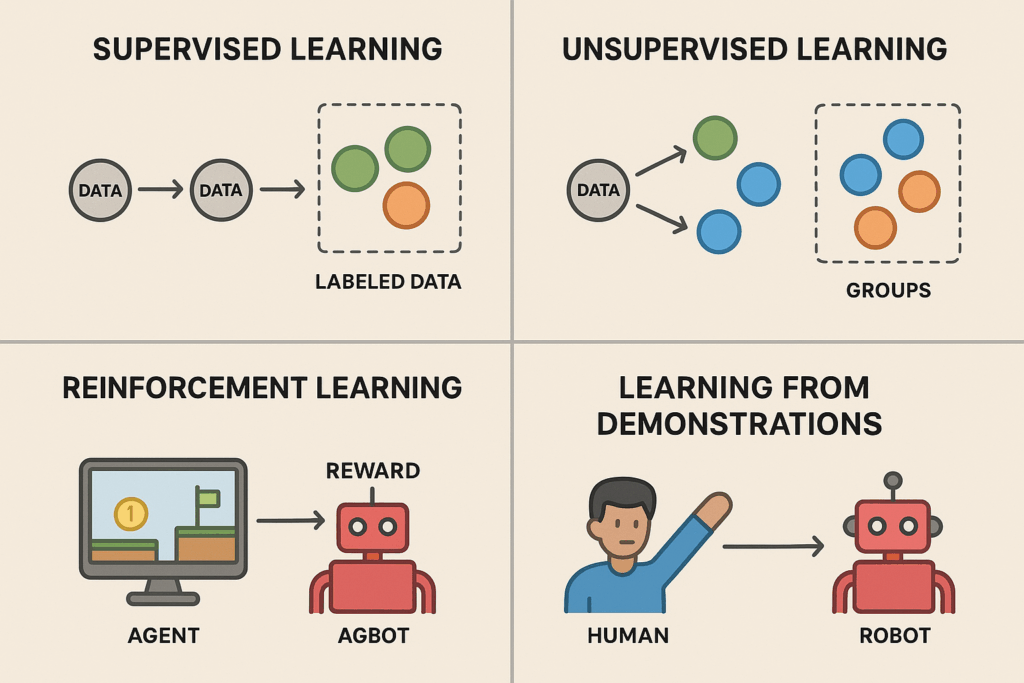
Tipos de aprendizaje en la IA
(supervisado, no supervisado, por refuerzo y por demostraciones)
Una vez vista la evolución histórica, pasamos a entender cómo “aprenden” los sistemas de inteligencia artificial. En términos sencillos, el aprendizaje en IA se refiere a cómo un algoritmo mejora su desempeño en una tarea a partir de datos o experiencia. Existen varios paradigmas de aprendizaje en el campo de la IA. En esta lección cubriremos cuatro de los más importantes: el aprendizaje supervisado, no supervisado, por refuerzo y por demostraciones. Cada uno de ellos tiene enfoques y aplicaciones distintas, que explicaremos a continuación con un lenguaje claro y ejemplos prácticos.
Aprendizaje supervisado
El aprendizaje supervisado es quizás el enfoque más utilizado en la industria actualmente. Se llama supervisado porque el algoritmo aprende a partir de ejemplos etiquetados; es decir, se le proporcionan datos de entrada junto con la respuesta correcta esperada. El objetivo del modelo es generalizar a partir de esos ejemplos de modo que, cuando se le dé un dato nuevo, pueda predecir la respuesta adecuada.
¿Cómo funciona? Imaginemos que queremos que una IA distinga entre correos “spam” y “no spam”. Primero recolectamos un gran conjunto de correos ya categorizados (etiquetados) como spam o legítimos. Ese conjunto es nuestro conjunto de entrenamiento. Se entrena un modelo (por ejemplo, un árbol de decisión o una red neuronal) mostrándole repetidamente cada correo y la etiqueta correcta. El modelo ajusta sus parámetros internos para minimizar los errores de predicción. Tras el entrenamiento, cuando llegue un correo nuevo sin etiqueta, el modelo podrá predecir si es spam basándose en lo que aprendió.
Aplicaciones comunes: clasificación de imágenes (por ejemplo, identificar si una foto contiene un gato o un perro), reconocimiento de voz (asociar un audio con el texto que se habló), detección de fraudes (predecir si una transacción es fraudulenta o no según casos históricos), traducción automática (con pares de frases equivalentes en dos idiomas), entre muchas otras. En cada caso, se dispone de datos con la respuesta correcta conocida para entrenar al sistema.
Ventajas y consideraciones: el aprendizaje supervisado suele lograr altos niveles de precisión cuando se tienen suficientes datos de calidad. Su principal limitación es precisamente la necesidad de datos etiquetados en cantidad, lo cual a veces es costoso de obtener. Además, si el modelo aprende de ejemplos que no son representativos del caso real (por ejemplo, si solo entrenamos un detector de spam con correos en inglés, quizás falle con correos en español), puede no generalizar bien. Aun así, gracias a la abundancia de datos en la era digital, este enfoque ha impulsado gran parte de los avances prácticos de la IA en las últimas décadas.
Aprendizaje no supervisado
En contraste con el anterior, el aprendizaje no supervisado se utiliza cuando no se dispone de etiquetas ni respuestas correctas en los datos. Aquí el algoritmo debe encontrar por sí mismo patrones, estructuras o relaciones interesantes dentro del conjunto de datos. Es como darle a la IA un puzzle sin decirle de antemano cuál es la imagen final; el sistema debe descubrir por su cuenta qué formas o grupos existen.
¿Cómo funciona? Un ejemplo típico es el agrupamiento (clustering). Supongamos que una empresa tiene datos de sus clientes (edad, hábitos de compra, ubicación, etc.) y quiere segmentarlos en grupos con características similares, para entender mejor su base de clientes. Un algoritmo no supervisado (como k-means o DBSCAN) puede analizar los datos y agrupar a los clientes en, digamos, 3 segmentos distintos, quizás encontrando grupos como “compradores jóvenes online”, “clientes empresariales grandes” y “consumidores esporádicos locales”. Importante: nadie le dijo al algoritmo cuántos ni qué tipo de grupos había; él los infiere buscando concentraciones de datos que se parezcan entre sí.
Otro tipo de tarea no supervisada es la reducción de dimensionalidad, donde el sistema busca formas de resumir o condensar datos complejos en representaciones más simples (por ejemplo, resumir miles de variables en unas pocas componentes principales que capturen la mayor variabilidad, usando técnicas como PCA).
Aplicaciones comunes: descubrimiento de clusters de clientes como vimos, detección de anomalías (lo que se sale de un patrón general, útil en seguridad o mantenimiento predictivo), compresión de datos, generación de datos sintéticos (algunas técnicas generativas comienzan con aprendizaje no supervisado de la estructura de los datos). Un caso cotidiano: los algoritmos de recomendaciones (por ejemplo, de películas o productos) a veces usan aprendizaje no supervisado para descubrir afinidades entre usuarios y productos sin que haya una “etiqueta” explícita, sino analizando comportamientos.
Ventajas y consideraciones: el aprendizaje no supervisado es útil para explorar lo desconocido en los datos. Puede revelar insights que no se habían considerado. La desventaja es que el resultado es más abierto y a veces difícil de evaluar automáticamente (¿cómo saber si los grupos descubiertos son “correctos”?), pues no hay una verdad exacta con la que comparar. Suele requerir interpretación humana para dar sentido a los patrones encontrados. Aun así, es un enfoque poderoso cuando solo se cuenta con muchos datos brutos sin anotar.
Aprendizaje por refuerzo
El aprendizaje por refuerzo (reinforcement learning, RL) es un paradigma inspirado en cómo aprenden los animales (y humanos) por prueba y error mediante recompensas y castigos. En este enfoque, un agente (por ejemplo, un programa de computadora que juega a un videojuego o que controla un robot) interactúa con un entorno. En cada paso, el agente realiza una acción y el entorno le devuelve una recompensa (que puede ser positiva, negativa o neutra) y un nuevo estado. El objetivo del agente es aprender una estrategia (policy) de acciones que maximice las recompensas acumuladas a largo plazo.
¿Cómo funciona? Imaginemos entrenar un agente para jugar Pac-Man. Al principio, el agente no sabe nada y tomará acciones al azar (moverse en alguna dirección). Cada vez que come un punto gana puntos (una recompensa positiva), si lo atrapa un fantasma pierde una vida (recompensa muy negativa). Con el tiempo, mediante algoritmos de refuerzo (como Q-learning o métodos con redes neuronales llamados Deep Q Networks), el agente va estimando qué acciones en qué situaciones le traen mayor recompensa esperada. Así, aprenderá comportamientos: por ejemplo, priorizar comer puntos y frutas, evitar a los fantasmas a menos que haya conseguido un poder para comerlos, etc. No hubo “ejemplos correctos” pre-etiquetados; el agente aprendió solo a base de experiencia y retroalimentación positiva/negativa.
Aplicaciones comunes: juegos y problemas de control han sido terreno fértil para el aprendizaje por refuerzo. Además del mencionado caso de AlphaGo (y AlphaZero que aprendió ajedrez y Go sin conocimiento previo humano), se usa en robótica (ej: enseñar a un robot a caminar, mantener equilibrio o agarrar objetos con retroalimentación), en sistemas de control industrial (aprender a calibrar maquinaria), en finanzas (agentes que aprenden estrategias de trading mediante recompensas simuladas), e incluso en optimización de procesos (por ejemplo, Google DeepMind lo aplicó para reducir consumo energético de data centers, donde la recompensa era la eficiencia).
Ventajas y consideraciones: el RL es especialmente potente para problemas secuenciales donde una acción influye en situaciones futuras. No requiere datos etiquetados de antemano, sino un entorno donde probar acciones. Sin embargo, también tiene desafíos: puede requerir muchísimas iteraciones de prueba (imaginemos cuántas partidas tuvo que jugar AlphaGo para alcanzar nivel campeón), y si la definición de recompensa no es adecuada, el agente podría aprender comportamientos indeseados. Además, los agentes de RL suelen ser sensibles a cambios en el entorno: lo que aprenden puede no transferirse si cambian las condiciones. Pese a ello, cuando se logra un buen entrenamiento, los resultados pueden superar incluso intuiciones humanas en problemas complejos.
Aprendizaje por demostraciones
El aprendizaje por demostraciones es un enfoque en el que un sistema aprende observando ejemplos de comportamiento realizados por un experto humano (u otro agente ya entrenado). En lugar de aprender únicamente de recompensas como en el refuerzo puro, aquí el agente aprovecha demostraciones ya hechas de la tarea para empezar con buen pie. Es similar a cuando un aprendiz observa a un maestro realizar una tarea antes de intentar hacerlo él mismo.
¿Cómo funciona? Supongamos que queremos entrenar un brazo robótico para organizar objetos en una caja. Podemos primero demostrar manualmente la tarea unas cuantas veces, moviendo el brazo nosotros (o tele-operándolo) para colocar correctamente los objetos. Esas grabaciones de movimientos y acciones exitosas se dan al agente como guías. Luego, el robot aplica aprendizaje por refuerzo o otros métodos para refinar su habilidad, partiendo de esas demostraciones en lugar de desde cero. Gracias a las demostraciones, el robot sabe de antemano que ciertos comportamientos conducen a la meta, reduciendo la exploración aleatoria inútil.
En el contexto de IA conversacional, podemos ver un ejemplo en cómo se entrenó inicialmente a ChatGPT: primero, se tomó un modelo de lenguaje y se afinó (fine-tuned) con conversaciones ejemplo realizadas por humanos (donde humanos hacían de usuario y de AI ideal), de modo que el modelo aprendiera formas adecuadas de responder antes de ser ajustado con refuerzo. Eso es aprendizaje por demostración a gran escala: usar datos de demostraciones humanas para guiar el comportamiento de la IA.
Aplicaciones comunes: robótica (como ilustramos), videojuegos (un agente puede aprender a jugar un nivel observando jugadas humanas registradas), asistentes virtuales (que pueden aprender de cómo un operador humano responde a ciertas consultas), y en general cualquier escenario donde conseguir algunas soluciones de ejemplo es más sencillo que definir una función de recompensa explícita o proporcionar millones de intentos.
Ventajas y consideraciones: la principal ventaja es que acelera el aprendizaje y puede conducir a mejores comportamientos iniciales, evitando que el agente “reinvente la rueda” mediante pura prueba y error. También puede incorporar directamente conocimiento humano (estrategias, atajos) en el agente. Por contra, hay que tener cuidado de no depender solo de las demostraciones; lo ideal suele ser combinarlas con refinamiento posterior. Además, si las demostraciones contienen errores o sesgos, el agente los aprenderá tal cual.
En suma, es una técnica muy útil para iniciar el entrenamiento de sistemas complejos, combinando lo mejor de la guía humana y la optimización automática.